For now, Java DB is actually just Apache Derby with a different name. In the following of the article, we will call it Derby. It comes with JDK installation. ( Although what's normally used in maven project is not the same binary install in local JDK directory)
Using embedded Java DB means the database will run in the same JVM as your application. The Java DB engine actually gets started when you try to connect to it by JDBC. When the application exits, the database also exits. If you choose to run the Java DB total in memory, when the JVM stops, the data will be gone. Or you can choose to store the data on local file system to make them usable during multiple runs.
Java DB (Derby) is mostly used for convenience in development. No external database is needed even you have code need to play with RMDB.
0. What you need
- JDK 6+ (JDK 7 in this demo)
- Maven 3.2 +
1. POM file
There's only one dependency needed to use Derby database.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.shengwang.demo</groupId>
<artifactId>javadb-derby-embedded-basic</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>javadb-derby-embedded-basic</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId>derby</artifactId>
<version>10.8.3.0</version>
</dependency>
</dependencies>
<!-- Use Java 1.7 -->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Since the version of Java DB comes with JDK 7 is 10.8.3.x, we also use 10.8.3.0 in our maven project. If just using in-memory database(see below), the version used in maven actually doesn't matter. But if database file stores on file system and you want to check the database content after application finishes, you'd better use the same version as from JDK, so the 'ij' tool in $JAVA_HOME/db/bin can open the database without version conflicts.
2. When the embedded database starts
The database starts when you java code try to connect to it by using standard JDBC. How the derby work depends on the way to connect to it, or in other words, depends on the connection url. Suppose we need to connect to a database named 'demo'.
In-memory database, url looks like: jdbc:derby:memory:demo;create=true
'demo' is the database name and can be any string you choose, "memory" is a key word to tell Derby to goes to all-in-memory mode.
File-based database, url looks like: jdbc:derby:c:\Users\shengw\MyDB\demo;create=true
'c:\Users\shengw\MyDB\demo' is the directory to save database files on local file system. (On windows its actually jdbc:derby:c:\\Users\\shengw\\MyDB\\demo;create=true because of the String escaping)
'create=true' is a Derby connection attribute to create the database if it doesn't exist. If use in-memory database, this attribute is mandatory.
3. A complete example
This is a complete hello world level example using embedded Derby database in Maven project. The HelloJavaDb.java lists below.
package com.shengwang.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class HelloJavaDb {
Connection conn;
public static void main(String[] args) throws SQLException {
HelloJavaDb app = new HelloJavaDb();
app.connectionToDerby();
app.normalDbUsage();
}
public void connectionToDerby() throws SQLException {
// -------------------------------------------
// URL format is
// jdbc:derby:<local directory to save data>
// -------------------------------------------
String dbUrl = "jdbc:derby:c:\\Users\\shengw\\MyDB\\demo;create=true";
conn = DriverManager.getConnection(dbUrl);
}
public void normalDbUsage() throws SQLException {
Statement stmt = conn.createStatement();
// drop table
// stmt.executeUpdate("Drop Table users");
// create table
stmt.executeUpdate("Create table users (id int primary key, name varchar(30))");
// insert 2 rows
stmt.executeUpdate("insert into users values (1,'tom')");
stmt.executeUpdate("insert into users values (2,'peter')");
// query
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
// print out query result
while (rs.next()) {
System.out.printf("%d\t%s\n", rs.getInt("id"), rs.getString("name"));
}
}
}
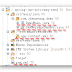
The demo uses derby database, creates a table 'users', inserts 2 rows into the table and prints the query result set. The whole maven project hierarchy is :

After running the HelloJavaDb example, you can verify the database, because we are not using derby in all-in-memory mode. After running, the database files will appear on local file system like this.

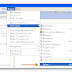
If you connect to the database in command line, you can see the 2 rows add from your Java code. 'ij' is a tool provided by Derby works as a sql client.