Netty is a NIO client server framework which enables quick and easy development of network applications. In this tutorial the basic concepts of Netty are introduced, as well as a hello world level example. This hello world example, based on Netty 4, has a server and a client, including heart beat between them, and POJO sending and recieving.
1. Concepts
Netty's high performance rely on NIO. Netty has serveral important conceps: channel, pipeline, and Inbound/Outbound handler. (
Channel can be thought as a tunnel that I/O request will go through. Every Channel has its own pipeline. On API level, the most used channel are io.netty.channel.NioServerSocketChannel for socket server and io.netty.channel.NioSocketChannel for socket client.
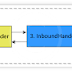
Pipeline is one of the most important notion to Netty. You can treat pipeline as a bi-direction queue. The queue is filled with inbound and outbound handlers. Every handler works like a servlet filter. As the name says , "Inbound" handlers only process read-in I/O event, "OutBound" handlers only process write-out I/O event, "InOutbound" handlers process both. For example a pipeline configured with 5 handlers looks like blow.

This pipeline is equivalent to the following logic. The input I/O event is process by handlers 1-3-4-5. The output is process by handes 5-2.

In real project, the first input handler, handler 1 in above chart, is usually an decoder. The last output handler, handler 2 in above chart, is usually a encoder. The last InOutboundHandler usually do the real business, process input data object and send reply back. In real usage, the last business logic handler often executes in a different thread than I/O thread so that the I/O is not blocked by any time-consuming tasks. (see example below)
Decoder transfers the read-in ByteBuf into data structure that is used in above bussiness logic. e.g. transfer byte stream into POJOs. If a frame is not fully received, it will block until its completion, so the next handler would NOT need to face a partial frame.
Encoder transfers the internal data structure to ByteBuf that will finally write out by socket.
How does the event flow through all the handler? One thing need to notice is that, every handler is reponsble to propagate the event to the next handler. One handler need to explicitly invoke a method of ChannelHanderContext to trigger the next handler to work. Those methods include:
Inbound event propagation methods:
- ChannelHandlerContext.fireChannelRegistered()
- ChannelHandlerContext.fireChannelActive()
- ChannelHandlerContext.fireChannelRead(Object)
- ChannelHandlerContext.fireChannelReadComplete()
- ChannelHandlerContext.fireExceptionCaught(Throwable)
- ChannelHandlerContext.fireUserEventTriggered(Object)
- ChannelHandlerContext.fireChannelWritabilityChanged()
- ChannelHandlerContext.fireChannelInactive()
- ChannelHandlerContext.fireChannelUnregistered()
Outbound event propagation methods:
- ChannelHandlerContext.bind(SocketAddress, ChannelPromise)
- ChannelHandlerContext.connect(SocketAddress, SocketAddress, ChannelPromise)
- ChannelHandlerContext.write(Object, ChannelPromise)
- ChannelHandlerContext.flush()
- ChannelHandlerContext.read()
- ChannelHandlerContext.disconnect(ChannelPromise)
- ChannelHandlerContext.close(ChannelPromise)
- ChannelHandlerContext.deregister(ChannelPromise)
The demo in this article use set a heart beat between client and server to keep the long connection. Netty's IdleStateHandler is used for heart beat on idle. In this IdleStateHandler, fireUserEventTriggered() is invoked to trigger the action of next handler.
2. Hello world example using Netty 4
This example has 1 server and 1 client. Long connection is used for data transfering. A heart beat message will be send from server to client if there is no data between them for every 5 seconds. The heart beat message has a timestamp of sending time. The client do nothing when get the heart beat but simply send it back to server. Server can print out the loopback delay by using recv time substract by sending time.
This example shows:
- How to send/recv POJOs with the help of encoder/decoder
- How to add heart beat for long connection.
The pipeline of demo server looks like below.

The IdleStateHandler is located at the very beginning so it can judge whether there is traffic in or out even the input traffic is in wrong frame format.
The pipeline of demo client looks like below.

2.1 Add netty dependency
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.0.34.Final</version>
</dependency>
Add netty to your pom.xml if maven is used.
2.2 Define Common Classes
There are 3 classes used both in server and client. A POJO class LoopBackTimeStamp.java which is sent and recieved, a encoder class TimeStampEncoder.java and a decoder class TimeStampDecoder.java
First the LoopBackTimeStamp.java
package com.shengwang.demo;
import java.nio.ByteBuffer;
public class LoopBackTimeStamp {
private long sendTimeStamp;
private long recvTimeStamp;
public LoopBackTimeStamp() {
this.sendTimeStamp = System.nanoTime();
}
public long timeLapseInNanoSecond() {
return recvTimeStamp - sendTimeStamp;
}
/**
* Transfer 2 long number to a 16 byte-long byte[], every 8 bytes represent a long number.
* @return
*/
public byte[] toByteArray() {
final int byteOfLong = Long.SIZE / Byte.SIZE;
byte[] ba = new byte[byteOfLong * 2];
byte[] t1 = ByteBuffer.allocate(byteOfLong).putLong(sendTimeStamp).array();
byte[] t2 = ByteBuffer.allocate(byteOfLong).putLong(recvTimeStamp).array();
for (int i = 0; i < byteOfLong; i++) {
ba[i] = t1[i];
}
for (int i = 0; i < byteOfLong; i++) {
ba[i + byteOfLong] = t2[i];
}
return ba;
}
/**
* Transfer a 16 byte-long byte[] to 2 long numbers, every 8 bytes represent a long number.
* @param content
*/
public void fromByteArray(byte[] content) {
int len = content.length;
final int byteOfLong = Long.SIZE / Byte.SIZE;
if (len != byteOfLong * 2) {
System.out.println("Error on content length");
return;
}
ByteBuffer buf1 = ByteBuffer.allocate(byteOfLong).put(content, 0, byteOfLong);
ByteBuffer buf2 = ByteBuffer.allocate(byteOfLong).put(content, byteOfLong, byteOfLong);
buf1.rewind();
buf2.rewind();
this.sendTimeStamp = buf1.getLong();
this.recvTimeStamp = buf2.getLong();
}
// getter/setter ignored
}
The LoopBackTimeStamp class has 2 long numbers. it also has 2 methods, toByteArray() is used to transfer the internal 2 long number into a byte array of 16 bytes. fromByteArray() works reversely, change 16 bytes array back to the 2 long numbers.
Then the encoder and decoder. The encoder TimeStampEncoder tranfer a LoopBackTimeStamp object into byte array that can be sent out.
package com.shengwang.demo.codec;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.MessageToByteEncoder;
import com.shengwang.demo.LoopBackTimeStamp;
public class TimeStampEncoder extends MessageToByteEncoder<LoopBackTimeStamp> {
@Override
protected void encode(ChannelHandlerContext ctx, LoopBackTimeStamp msg, ByteBuf out) throws Exception {
out.writeBytes(msg.toByteArray());
}
}
The decoder transfer bytes recieved from socket into a LoopBackTimeStamp object for business handler to process.
package com.shengwang.demo.codec;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.ByteToMessageDecoder;
import java.util.List;
import com.shengwang.demo.LoopBackTimeStamp;
public class TimeStampDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
final int messageLength = Long.SIZE/Byte.SIZE *2;
if (in.readableBytes() < messageLength) {
return;
}
byte [] ba = new byte[messageLength];
in.readBytes(ba, 0, messageLength); // block until read 16 bytes from sockets
LoopBackTimeStamp loopBackTimeStamp = new LoopBackTimeStamp();
loopBackTimeStamp.fromByteArray(ba);
out.add(loopBackTimeStamp);
}
}
The decoder try to read 16 bytes as a whole, then create a LoopBackTimeStamp object from this 16 bytes array. It blocks if less than 16 bytes recieved, until a complete frame recieved.
2.3 Define server classes
Besides the above 3 common classes, server and client both have 2 own classes respectively, Main + a Handler for real logic. The logic handler for server, ServerHandler.java, is as follows.
package com.shengwang.demo;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelInboundHandlerAdapter;
import io.netty.handler.timeout.IdleState;
import io.netty.handler.timeout.IdleStateEvent;
public class ServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
LoopBackTimeStamp ts = (LoopBackTimeStamp) msg;
ts.setRecvTimeStamp(System.nanoTime());
System.out.println("loop delay in ms : " + 1.0 * ts.timeLapseInNanoSecond() / 1000000L);
}
// Here is how we send out heart beat for idle to long
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
IdleStateEvent event = (IdleStateEvent) evt;
if (event.state() == IdleState.ALL_IDLE) { // idle for no read and write
ctx.writeAndFlush(new LoopBackTimeStamp());
}
}
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
// Close the connection when an exception is raised.
cause.printStackTrace();
ctx.close();
}
}
All three methods are overriden methods. The first channelRead() read loop back message and print out time spent on the trip. The second method handle the event fired by IdleStateHandler (you may want to scroll up to review how server pipeline configured). When idle too long, a LoopBackTimeStamp object is sent out as heart beat.
Another class for server is a main class NettyServer.java.
package com.shengwang.demo;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.ChannelOption;
import io.netty.channel.ChannelPipeline;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.handler.timeout.IdleStateHandler;
import io.netty.util.concurrent.DefaultEventExecutorGroup;
import io.netty.util.concurrent.EventExecutorGroup;
import java.io.IOException;
import com.shengwang.demo.codec.TimeStampDecoder;
import com.shengwang.demo.codec.TimeStampEncoder;
public class NettyServer {
public static void main(String[] args) throws IOException, InterruptedException {
NioEventLoopGroup boosGroup = new NioEventLoopGroup();
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(boosGroup, workerGroup);
bootstrap.channel(NioServerSocketChannel.class);
// ===========================================================
// 1. define a separate thread pool to execute handlers with
// slow business logic. e.g database operation
// ===========================================================
final EventExecutorGroup group = new DefaultEventExecutorGroup(1500); //thread pool of 1500
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast("idleStateHandler",new IdleStateHandler(0,0,5)); // add with name
pipeline.addLast(new TimeStampEncoder()); // add without name, name auto generated
pipeline.addLast(new TimeStampDecoder()); // add without name, name auto generated
//===========================================================
// 2. run handler with slow business logic
// in separate thread from I/O thread
//===========================================================
pipeline.addLast(group,"serverHandler",new ServerHandler());
}
});
bootstrap.childOption(ChannelOption.SO_KEEPALIVE, true);
bootstrap.bind(19000).sync();
}
}
Most of the main codes are boilerplate of how to init a netty sever, pay attention to how to add thoese handlers to the pipeline and how to run business logic handler in separated thread.
2.4 Define client classes
Client, like server, also has 2 classes. main + a handler. The ClientHandler class, like ServerHandler class, is also a "Inbound handler", only process income message.
package com.shengwang.demo;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelInboundHandlerAdapter;
public class ClientHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
LoopBackTimeStamp ts = (LoopBackTimeStamp) msg;
ctx.writeAndFlush(ts); //recieved message sent back directly
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
// Close the connection when an exception is raised.
cause.printStackTrace();
ctx.close();
}
}
The client reads message and directly send it back for loopback.
The main class for client, NettyClient.java, shows below.
package com.shengwang.demo;
import io.netty.bootstrap.Bootstrap;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import com.shengwang.demo.codec.TimeStampDecoder;
import com.shengwang.demo.codec.TimeStampEncoder;
public class NettyClient {
public static void main(String[] args) {
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
Bootstrap b = new Bootstrap();
b.group(workerGroup);
b.channel(NioSocketChannel.class);
b.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new TimeStampEncoder(),new TimeStampDecoder(),new ClientHandler());
}
});
String serverIp = "192.168.203.156";
b.connect(serverIp, 19000);
}
}
The demo client connect to a hard code ip and port.
Finally the project hierarchy looks like:

3. Run it
First let's run the server, then open another windows to run client. After client connected, you see every 5 seconds, a loop back trip message is print out on screen.

Furthurmore, this demo is also used to coarsely estimate the hardware requirement in our project for a server support large long connection clients. When running the NettyServer on a server with 2 CPU (Xeon E5-2650 2.0GHZ, 20M Cache, 8 core, 16 threads) and 32G RAM. the work load looks like below with 264,000 connections.

6 hosts are used as client to run NettyClient. So every host has about 40,000 connections. The connections on the same client host trigger heart beat at the same time, so the cpu usage roughly relects this workload. If the heart beat can be scattered a little, the cpu workload drops clearly.