Liquibase is a dabasebase chane management tool. Rather than writing SQL directly against the database to create, update or drop database objects, developers define their desired database changes in XML files.
Any change to database are grouped into "ChangeSet", the best practice is one changeset per modification to make roll back easily. Changes to database can be taged. e.g, you can tag you database structure to 1.0 after first release. Later, when some patches are made and ver 1.1 is release, you can tag all changes up to now to 1.1. (If it's not very clear now, it's ok, see the examples below will make it more obvious). With the help of those tags, you can easy rollback you database structure back to a certain version. (Also, liquibase can roll back without tags).
One notion need to be clarified first, liquibase only manage schema changes of your database, e.g. add extra index or rename a column, the data in the tables are not managed!
1. Basic concepts
ChangeSet is a logic group in which you can put any real operation. For example, a change set can has operations to create a table, rename a column, add foreign key or any other database operations.
How does liquibase identify a change set? changeset is identified by 3 elements, id + author + change log filename(with path). When run liquibase first time, it will create 2 extra tables in your database, databasechangelog and databasechangeloglock.

Liquibase will go through changelog xml file, see if there are some change sets not in this table. If found, execute them and put a recored in this table. By using this table, liquibase can trace which changeset has already executed, which changeset is new. Tags can be used to specifiy a version you want to go, see below example for more. To use liquibase, you don't need to touch this databasechangelog table, but it can help you understand how liquibase works.
To use liquibase, you also need a change log file, in which all database operations are defined. In this tutorial, liquibase 3.4 and xml based change log is used.
2. How to run liquibase
Before the demo starts, let's first see how to run liquibase. In this tutorial, 2 ways are introduced, by command line or by maven plugin.
To run liquibase in command line, you need
- download liquibase, unpack it executable file liquibase or liquibase.bat in the package.
- download your database jdbc driver to you local disk.
To run liquibase by using maven, you need:
- change pom file, add liquibase-maven-plugin
Since in pom.xml the jdbc driver dependency has already be added, you don't need the external jdbc jar file.
You can choose either command line or maven plugin to run liquibase. I personally perfer by maven plugin, cause the command can be much shorter.
3. Hello world demo for liquibase usage
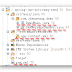
First let's create a maven project in eclipse. In this demo there's no java class. We emphase on how to use liquibase. The hierarchy of the demo project looks like below.

Let's go through these files one by one.
3.1 pom.xml
First the pom.xml, to add liquibase plugin. If you decide no to use maven to run liquibase, this step can be omitted.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sanss.demo</groupId>
<artifactId>liquibase-helloworld-demo</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>liquibase-helloworld-demo</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- MySQL -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
</dependencies>
<build>
<finalName>liquibase-helloworld-demo</finalName>
<plugins>
<!-- Use Java 1.7 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<!-- User liquibase plugin -->
<plugin>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-maven-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<propertyFile>liquibase/liquibase.properties</propertyFile>
<changeLogFile>liquibase/db-changelog-master.xml</changeLogFile>
</configuration>
<!-- I personally prefer run it manually
<executions>
<execution>
<phase>process-resources</phase>
<goals>
<goal>update</goal>
</goals>
</execution>
</executions>
-->
</plugin>
</plugins>
</build>
</project>
I personally perfer no to bind it to any maven build lifecycle, but invoke it manually. There are 2 files configured in this plugin, "peroperties file" defines all parameter to connect a database. "changeLogFile" is the file from which it read the change sets.
3.1 liquibase.properties
This file has all connection parameters. Here is the liquibase.properites file in this demo.
# MySQL
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/spring
username=root
password=yourPwdToDatabase
Nothing fancy here, just common database connection parameters.
3.2 ChangeLog files
In this demo, change log files are in xml format. Other avaiable formats are json and yaml.
The official recommand best practice is always using a xxxx-master.xml file as an entry file. This is also the file set in the maven plugin. In this db-changelog-master.xml file, there's no real logic defined, only a bunch of includes.
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.4.xsd">
<include file="liquibase/db-changelog-1.0.xml"/>
<include file="liquibase/db-changelog-1.1.xml"/>
<include file="liquibase/db-changelog-1.2.xml"/>
</databaseChangeLog>
The included files have all change sets. Suppose the file db-changelog-1.0.xml is the database structure for release version 1.0.
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.4.xsd">
<changeSet id="create_department" author="sheng.w">
<createTable tableName="department">
<column name="id" type="int">
<constraints primaryKey="true" nullable="false" />
</column>
<column name="name" type="varchar(50)">
<constraints nullable="false" />
</column>
</createTable>
</changeSet>
<changeSet id="create_employee" author="sheng.w">
<createTable tableName="employee">
<column name="id" type="int">
<constraints primaryKey="true" nullable="false" />
</column>
<column name="emp_name" type="varchar(50)">
<constraints nullable="false" />
</column>
<column name="dept" type="int"/>
</createTable>
</changeSet>
<changeSet id="tag-1.0" author="sheng.w">
<tagDatabase tag="1.0" />
</changeSet>
</databaseChangeLog>
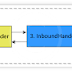
There are 3 change sets in our 1.0 database schema. Two tables are created and a tag for version 1.0 is added in the end. Every change set has an id and an author. This xml file demostrate how to create table and primary key for it. The result up to version 1.0 is 2 tables in the database.

Let suppose later on, 2 new versions are released with a little change to the database, 1.1 and 1.2. Every version has a xml file, defining what has changed since last time. The db-changelog-1.1.xml change column 'name' of table 'department' to 'dept_name'
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.4.xsd">
<changeSet id="rename_dept_column" author="sheng.w">
<renameColumn tableName="department" oldColumnName="name" newColumnName="dept_name" columnDataType="varchar(50)"/>
</changeSet>
<changeSet id="tag-1.1" author="sheng.w">
<tagDatabase tag="1.1" />
</changeSet>
</databaseChangeLog>
The result up to 1.1 in database is

Later in version 1.2, one index adds to empolyee table, one foreign key adds between employee and department.
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.4.xsd">
<changeSet id="add-fk-between-emp-and-dept" author="sheng.w">
<addForeignKeyConstraint constraintName="fk_emp_dept"
baseTableName="employee" baseColumnNames="dept" referencedTableName="department"
referencedColumnNames="id" onDelete="CASCADE" onUpdate="CASCADE" />
</changeSet>
<changeSet id="add_index" author="sheng.w">
<createIndex tableName="employee" indexName="idx_exp_name">
<column name="emp_name"/>
</createIndex>
</changeSet>
<changeSet id="tag-1.2" author="sheng.w">
<tagDatabase tag="1.2" />
</changeSet>
</databaseChangeLog>
Up to version 1.2, the database looks like below.

4. Understand version control of liquibase
Let's now demostrate the 'version control' function of liquibase. Suppose at beginning we have a clean database with nothing in it. The database change log has 3 versions, 1.0, 1,1 and 1.2 defined in previouse chapter. latest version is 1.2.
- version 1.0, create 2 tables
- version 1.1, change column name of table department
- version 1.2, add foreign key and index
4.1 Apply change log to database until latest
First let create database schema to current latest version. Using command line:
liquibase --defaultsFile=src/main/resources/liquibase/liquibase.properties \
--classpath="d:\mysql-connector-java-5.1.6.jar;D:\spring-learning\liquibase-helloworld-demo\target\liquibase-helloworld-demo.jar" \
--changeLogFile=liquibase/db-changelog-master.xml \
update
The defaultsFile specify the location of properties file for database connection. classpath specify where to find all necessary java file and xml change log files. Here are 2 jar files, one is mysql jdbc driver, the other is the jar of our demo, from which to read the changelog xml file. changeLogFile specify the file name of change log. update is the command for liquibase, to update database according to the xml change log file.

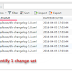
Now check the database, in databasechangelog table, all change set are executed.

I personally like to run liquibase by maven, because the command is much shorter. The following maven command is equivalent to the previsou command line.
mvn liquibase:update

4.2 Rollback database to version 1.0
For some reason you want to roll back you database to verion 1.0. You can achieve that by command line
liquibase --defaultsFile=src/main/resources/liquibase/liquibase.properties \
--classpath="d:\mysql-connector-java-5.1.6.jar;D:\spring-learning\liquibase-helloworld-demo\target\liquibase-helloworld-demo.jar" \
--changeLogFile=liquibase/db-changelog-master.xml \
rollback 1.0
or by maven command
mvn liquibase:rollback -Dliquibase.rollbackTag=1.0
These 2 ways to are equivalent, just pay attention to how to specify the version tag

If you check the databasechangelog table, you will found the changeset after 1.0 are all gone.

The tables are also revers to what they looks like in verion 1.0, now foreign key and with orignal column name.

4.3 apply change log to a specified version
Now the database is in status 1.0, and you want to apply 1.1 to it. you can do that by following command.
liquibase --defaultsFile=src/main/resources/liquibase/liquibase.properties \
--classpath="d:\mysql-connector-java-5.1.6.jar;D:\spring-learning\liquibase-helloworld-demo\target\liquibase-helloworld-demo.jar" \
--changeLogFile=liquibase/db-changelog-master.xml \
updateToTag 1.1
By using sub command updateToTag, you can update database to a certain version tag.

The above command line also equals to following maven command:
mvn liquibase:update -Dliquibase.toTag=1.1
Let's verify the database.

Tables ae also in the 1.1 status, no 1.2 foreign key yet, but get 1.1 column rename done.

Now you should have some feelings on how liquibase can do the 'version control'
5. Generate ChangeLog from existent tables
If you already have everything configured in database by hand or sql. You can use liqubase to generate change log file for you, then you can keep working based on the generated xml.
By command line:
liquibase --defaultsFile=src/main/resources/liquibase/liquibase.properties \
--classpath="d:\mysql-connector-java-5.1.6.jar;D:\spring-learning\liquibase-helloworld-demo\target\liquibase-helloworld-demo.jar" \
--changeLogFile=d:\output.xml \
generateChangeLog
The changeLogFile is a filename to be created. The file name must end with ".xml", ".json" or ".yaml".
By maven plugin:
mvn liquibase:generateChangeLog -Dliquibase.outputChangeLogFile=d:\output.xml
The options to specify output name are different in command line and maven plugin. After running you should be able to find newly create d:\output.xml file
6. Recap
Now you should be able to:
- understand how liquibase workds
- how to create table, pk, fk, index in xml format in change log file
- how to apply change log to datebase
- how to rollback and do version control with liquibase
- how to generate change log from existent tables