In this article, there is 3 hello world level demos. The difference is where does the spark get its input data.
- The first one, spark get its input data from external socket server. This method is often used in testing or developing phase.
- The second demo, spark get its input data from Flume agent.
- The third one, spark get its input data from Kafka. The last one may be used more common in real project.
1. Brief
Flume,Spark, Kafka are all apache projects.
Flume is mainly designed to move data, large amount of data, from one place to another, especially from Non-Big-Data-World to Big-Data-World. e.g. from log file to HDFS. Usually the role of Flume agent in the cluster is data producer.
Spark is designed to process large scale data in a near-real-time way. Input data will be process in consecutive batch of operations, usually these operation are map-reduce. If the batch interval set to 10 seconds, a map-reduce operation can process the data coming at that time windows every 10 seconds. An working scenario is using spark 's input is infinite stream of lines of web access log. Usually the role of Spark in the cluseter is data consumer.
Kafka, like a JMS in traditional non big data application, can be used to connect Flume, namely producer, to Spark, namely consumer.
2. Spark demos
All three spark demo just get input from stream and print out to screen. Every demo is very simple, only has one main class. You can replace the print out with some real task in your own use. In this article all demos run on CDH release 5.4.9. (flume 1.5.0, spark 1.3.0, kafka 2.0 )
Pay attention to how they get input stream as well as how to process the stream. The generic types of the stream are different, which are String, FlumeEvent and Tuple2<String,String> for demo1, 2, 3 respectively.
2.1 Data from external socket server.
In demo1, Spark gets its input from a external socket server. Add dependency to spark-streaming_xxx to you pom.
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.3.0</version>
</dependency>
The main class is defined like below.
package com.shengwang.demo;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
public class NakedSparkMain {
private static final int INTERVAL = 5000;
private static final String DATA_HOST = "localhost";
private static final int DATA_PORT = 11111;
public static void main(String[] args) {
NakedSparkMain main = new NakedSparkMain();
main.createJavaStreamingDStream();
}
private void createJavaStreamingDStream() {
// =========================================
// init Streaming context
// =========================================
SparkConf conf = new SparkConf().setAppName("naked-spark application");
JavaStreamingContext ssc = new JavaStreamingContext(conf, new Duration(INTERVAL));
// =========================================
// Data input - get data from socket server
// =========================================
JavaReceiverInputDStream<String> stringStream = ssc.socketTextStream(DATA_HOST, DATA_PORT);
// =========================================
// Data process part - print every line
// =========================================
stringStream.foreach(x -> {
x.foreach(y -> {
System.out.println("----- message -----");
System.out.println("input = " + y);
});
return null;
});
ssc.start();
ssc.awaitTermination();
}
}
2. 2 Data from Flume sink
In demo2, Spark gets its input from a flume avro agent. Add dependency to spark-streaming-flume_xxx to you pom.
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.10</artifactId>
<version>1.3.0</version>
</dependency>
The main class is defined like below.
package com.sanss.qos.spark.stream.flume;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.flume.FlumeUtils;
import org.apache.spark.streaming.flume.SparkFlumeEvent;
public class FlumeMain {
private static final int INTERVAL = 5000;
private static final String FLUME_HOST = "localhost";
private static final int FLUME_PORT = 11111;
public static void main(String[] args) {
FlumeMain main = new FlumeMain();
main.createJavaStreamingDStream();
}
private void createJavaStreamingDStream() {
// =========================================
// init Streaming context
// =========================================
SparkConf conf = new SparkConf().setAppName("flume-to-spark application");
JavaStreamingContext ssc = new JavaStreamingContext(conf, new Duration(INTERVAL));
// =========================================
// Data input - get data from flume agent
// =========================================
JavaReceiverInputDStream<SparkFlumeEvent> flumeStream = FlumeUtils.createStream(ssc, FLUME_HOST, FLUME_PORT);
// =========================================
// Data process part - print every line
// =========================================
flumeStream.foreach(x -> {
x.foreach(y -> {
System.out.println("----- message -----");
System.out.println("input = " + getMessageFromFlumeEvent(y));
});
return null;
});
ssc.start();
ssc.awaitTermination();
}
private String getMessageFromFlumeEvent(SparkFlumeEvent x) {
return new String (x.event().getBody().array());
}
}
This demo hardcode the flume sink ip and port to localhost and 11111, make sure the flume configuration match the code.
2.3 Data from Kafka
In demo3, Spark gets its input from kafka topic. Add dependency to spark-streaming-kafka_xxx to you pom.
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.3.0</version>
</dependency>
The main class is defined like below.
package com.sanss.qos.spark.stream.flume;
import java.util.HashMap;
import java.util.Map;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
public class KafkaSparkMain {
private static final int INTERVAL = 5000;
private String zookeeper = "cdh01:2181"; // hardcode zookeeper
private String groupId = "qosTopic";
private String topicName = "mytopic1";
private Map<String, Integer> topics = new HashMap<>();
public static void main(String[] args) {
KafkaSparkMain main = new KafkaSparkMain();
main.createJavaStreamingDStream();
}
private void createJavaStreamingDStream() {
// =========================================
// init Streaming context
// =========================================
SparkConf conf = new SparkConf().setAppName("kafka-to-spark application");
JavaStreamingContext ssc = new JavaStreamingContext(conf, new Duration(INTERVAL));
// =========================================
// Data input - get data from kafka topic
// =========================================
topics.put(topicName, 1);
JavaPairReceiverInputDStream<String, String> kafkaStream = KafkaUtils.createStream(ssc, zookeeper, groupId, topics);
// =========================================
// Data process part - print every line
// =========================================
kafkaStream.foreach(x -> {
x.foreach(y -> {
System.out.println("----- message -----");
System.out.println("input = " + y._1 + "=>" + y._2);
});
return null;
});
ssc.start();
ssc.awaitTermination();
}
}
This demo hardcode read data from a kafka topic 'mytopic1', make sure you have data published to that topic.
3. Run the demo
For simplicity, only run the first one, the other 2 result same but need more external environment. The first one only need a external socket server, like linux netcat tool can do this for you. That's also why the first one can be very convenient during developing phase.
First let's start a socket server listen on port 1111 with netcat.

Now start our spark application on a server with spark installed.
spark-submit --master local[*] --class com.shengwang.demo.NakedSparkMain /usr/sanss/qos-spark-1.0.jar
After spark application runs, you will find it dump a lot of log every 5 seconds, because we set the batch duration is 5 seconds in programe. Now type something in netcat window

You will see the message pring out in spark outout like below.


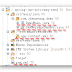





hi sheng.
ReplyDeletehow can i run first example in windows environment. please help. not getting data